

Five Blind Spots in the AI Replacement Thesis - The human 'ingenunity' factor
Everyone is modelling the cost of AI agents. Almost nobody is modelling what disappears from the organization when the humans leave.

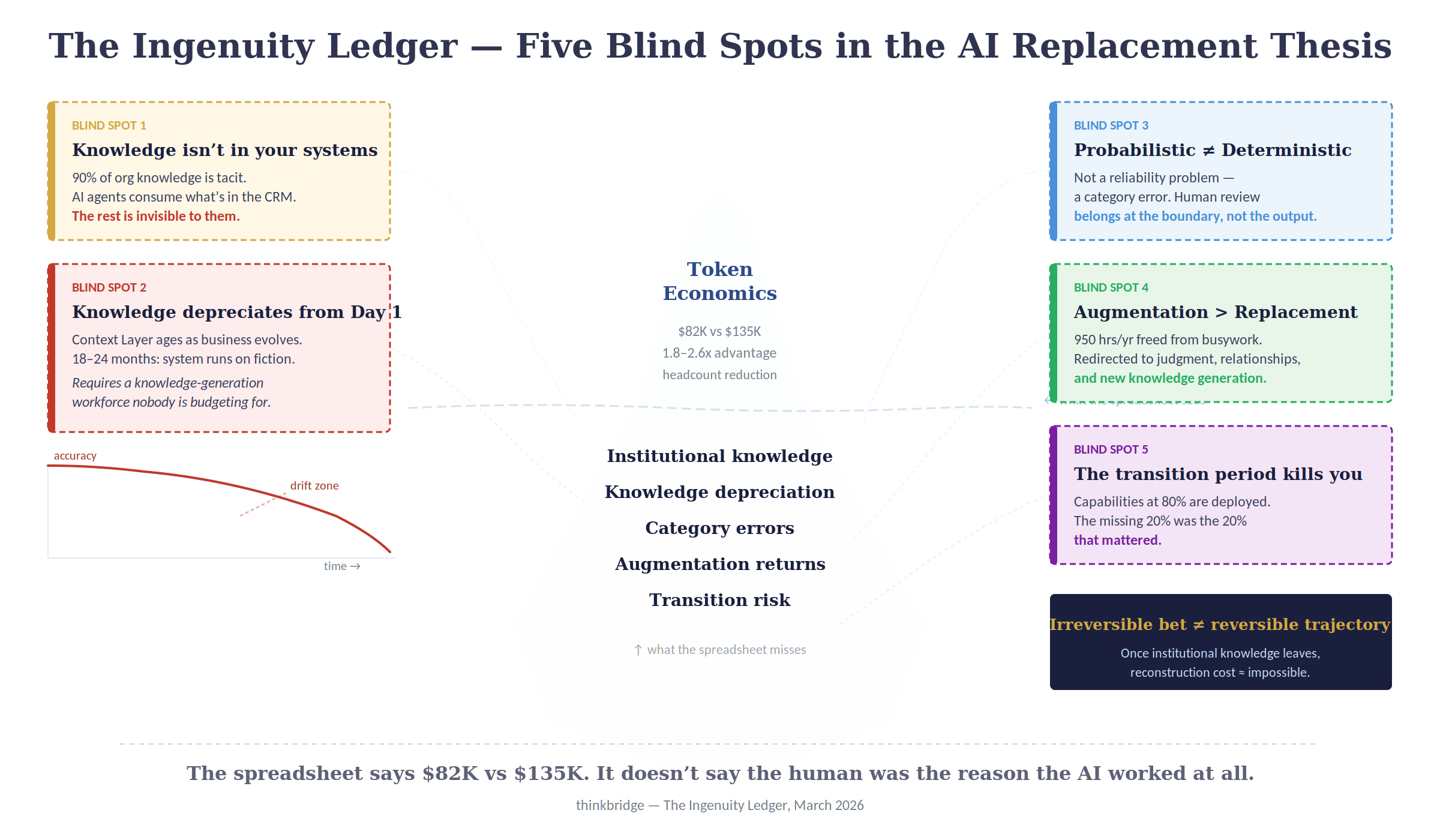
The AI replacement thesis has a compelling spreadsheet behind it. In a companion analysis — The Token Economy — I built that spreadsheet: token consumption, infrastructure costs, error and risk layers, five-year forecasts across three pricing scenarios. The fully loaded cost of an AI agent comes to roughly $82,000 per year at a 20-agent mid-market deployment, against $135,000 for the human it replaces. Even after accounting for subsidized token pricing, hallucination risk, and the full infrastructure stack, the economics deliver a 1.8–2.6x cost advantage at scale.
That analysis deliberately excluded a variable it could not price. This article is about that variable — and about five specific blind spots in the market’s current thinking that, if unaddressed, will cause the most sophisticated AI deployments to fail in ways their ROI models never predicted.
These are not speculative risks. They are structural consequences of how probabilistic systems interact with the accumulated knowledge of human organizations. The market is not ignoring them because they are unimportant. It is ignoring them because they are hard to quantify, and the things that are easy to quantify — token costs, headcount reduction, inference latency — are consuming all the analytical oxygen.
Blind Spot 1: Institutional Knowledge Is Not in Your Systems
The most immediate risk in AI substitution is not hallucination, not token price escalation, not infrastructure cost overruns. It is the silent evaporation of institutional knowledge — the accumulated understanding of how the business actually operates, as distinct from how it is documented to operate.
The scale of this problem is empirically established. Research on knowledge management consistently finds that approximately 90% of total organizational knowledge is held in tacit form — skills, instincts, and contextual understanding that live in employees’ heads and have never been written down. A study on workplace knowledge sharing estimated that the average US business loses $47 million in productivity annually due to inefficient knowledge transfer, and that 42% of institutional knowledge is unique to the individual employee’s role and unknown to their coworkers. An organisation with 30,000 employees can expect to lose $72 million per year in productivity from knowledge-related inefficiencies. SHRM estimates the total replacement cost per employee at three to four times annual salary — a figure that captures recruitment and onboarding but drastically undervalues the institutional knowledge that departed with the prior occupant.
These numbers describe normal turnover. AI substitution is not normal turnover.
When one human replaces another, the new arrival gradually absorbs institutional knowledge through osmosis — watching how colleagues handle edge cases, asking questions in hallway conversations, learning through error which documented procedures to follow and which to quietly ignore. This absorption process is slow, inefficient, and rarely deliberate. But it works. Over 6–18 months, the replacement employee develops a functional approximation of the departed employee’s contextual understanding.
An AI agent has no mechanism for this absorption. It consumes what is in the CRM, the ticketing system, the knowledge base, and whatever context has been architecturally provided. Everything else — the client who always exaggerates urgency, the product line with an undocumented failure mode under certain humidity conditions, the VP who treats Slack messages about financial matters as a personal affront — is invisible to the agent. The agent does not know what it does not know. It handles the escalation using the data it has and produces a response that is technically correct and contextually disastrous.
This is where the analysis connects to the architectural framework in The Modern AI Construct. That framework argues that most organizations deploying AI are assembling capable components on weak foundations, in the wrong order, without the governance structures that determine whether the system fails visibly or silently. Its five-layer architecture — Systems of Record, Context Layer, Agents, Orchestration, and Systems of Engagement — places data quality and context architecture at the bottom, because these layers constrain every layer above them.
Institutional knowledge is a Context Layer problem. The knowledge exists. It is real, consequential, and in most organizations, architecturally invisible. The organizations that build the Context Layer before deploying agents will produce AI systems that compound in capability over time. The ones that skip to agents and interfaces — which is what the vendor demo encourages, because it is the visually impressive part — will produce systems that are confidently wrong in exactly the ways the departed human employees would have caught.
A critical nuance: institutional knowledge exists on a spectrum from fully documentable to fully experiential. At one end, explicit knowledge — pricing rules, compliance checklists, standard operating procedures — already lives in systems of record or can be readily captured. At the other end, deeply tacit knowledge — the gut feeling that something is wrong in the Chicago warehouse when every metric reads green — cannot be externalized regardless of how much effort is applied. Between these extremes lies a large middle band of knowledge that is not currently documented but could be with deliberate architectural effort: client relationship histories richer than CRM entries, product-specific tribal knowledge that engineers carry but never formalise, process exceptions that experienced operators navigate from muscle memory. The Context Layer targets this middle band. It will not capture everything. It does not need to. It needs to capture enough to prevent the most frequent and most damaging contextual failures.
The organizations that fail to build this layer will not know they have failed until the AI system has been producing confidently wrong outputs for months — because the person who would have noticed the errors fastest is the person who was just replaced.
Blind Spot 2: The Knowledge Depreciation Clock Starts on Day One
This is the observation that the market has almost entirely missed, and it is the most strategically consequential idea in this analysis.
The institutional knowledge that an AI agent uses to handle a complex task had to come from somewhere. It came from humans — employees who spent years developing contextual understanding through direct experience. When those humans are replaced, the knowledge they contributed to the AI system becomes a fixed asset. And like all fixed assets, it depreciates.
The depreciation is invisible at first. For the first 6–12 months after deployment, the AI system performs well because the institutional knowledge embedded in its Context Layer is fresh and accurate. Clients have not changed their preferences. Products have not been updated. Regulations have not shifted. The business the AI was trained on still resembles the business it is serving.
Then the drift begins. A major client restructures their procurement team, and the relationship dynamics that informed the AI’s escalation logic no longer apply. A new product launches with characteristics that the knowledge base does not reflect. A regulatory change alters the compliance workflow in ways the AI’s training data does not capture. Each of these changes is individually manageable. Collectively, over 18–24 months, they produce a system that is operating on an increasingly fictional model of the business.
The system does not announce this drift. It continues to produce outputs with the same confidence it displayed on day one. The outputs are simply wrong more often, in ways that are difficult to detect because the wrongness is contextual rather than factual. The AI agent still cites the correct policy; it just applies it to a client situation that no longer matches the pattern it learned.
This is the ingenuity paradox: the value AI extracts from human institutional knowledge is a depreciating asset that requires ongoing human input to refresh. Organizations that cut too deep into their human workforce to maximize short-term token economics will find, within two years, that their AI systems are operating on stale knowledge, producing outputs that reflect a business that no longer exists.
The paradox has a direct workforce-sizing implication that no AI deployment model currently accounts for. Every AI deployment requires what might be called a knowledge generation function — a human workforce whose primary role is not to produce the routine output the AI now handles, but to generate the new institutional knowledge that keeps the AI system current. This is a fundamentally different job description from the one the replaced employees held. The replaced employee’s job was to do the work. The knowledge-generation employee’s job is to understand the work’s context deeply enough to keep the AI’s context layer accurate as the business evolves.
How large must this knowledge-generation workforce be? The answer depends on the rate of contextual change in the business. A stable, slow-moving industry (utilities, basic manufacturing) might sustain a 10:1 ratio — ten AI agents supported by one knowledge-generating human. A fast-moving, relationship-intensive industry (professional services, technology sales, financial advisory) might require 4:1 or even 3:1. No AI deployment model currently includes this workforce. It does not appear in any vendor’s ROI calculator. It is the line item the market has not yet learned to budget for.
The early warning signals that the knowledge depreciation clock has outrun the knowledge generation capacity are specific and observable: rising exception rates in AI agent outputs, increasing escalation frequency to human reviewers, growing divergence between AI-recommended actions and human-overridden actions, and — most dangerously — declining customer satisfaction scores in segments served by AI agents, without any corresponding decline in the metrics the AI was optimised to maintain. The last signal is the most important, because it reveals the fundamental failure mode: the AI is optimizing metrics that no longer capture what matters.
Blind Spot 3: The Probabilistic-Deterministic Category Error
The market has largely absorbed the idea that AI agents hallucinate. What it has not absorbed is the more consequential architectural point: AI agents built on large language models are probabilistic systems, and deploying them in deterministic contexts — workflows requiring consistency, auditability, or precise computation — is not a reliability problem. It is a category error.
A reliability problem can be solved by improving the model. A category error cannot, because the model is being used for something it was not designed to do. Asking a probabilistic system to produce guaranteed-correct outputs is like asking a weather forecast to be a schedule. The forecast can be highly accurate; it is still not the same category of thing as a commitment.
The correct architecture, as laid out in The Modern AI Construct, places the probabilistic layer upstream and the deterministic layer downstream. The AI agent resolves ambiguity — interpreting what the customer is asking, triaging a request by urgency, understanding the intent behind an email. Then a deterministic system enforces correctness — applying the right pricing rule, routing to the right escalation path, calculating the right financial figure. Human review sits at the confidence threshold boundary between them.
The placement of human review is the critical design decision that most deployments get wrong. In the typical deployment, human review sits at the system’s output — the end of the chain. A human checks the AI’s work after the AI has produced a complete response. This is expensive (the human must understand the full context to evaluate the output), slow (review happens after the work is done, not during), and wasteful (when errors are caught at the output, the entire chain of work that produced them must be discarded or reworked).
In the correct architecture, human review sits at the confidence boundary — the point where the probabilistic system’s confidence drops below a threshold. The AI agent handles the 85% of cases where it is confident. It escalates the 15% where it is not. The human reviews only the ambiguous cases, applying judgment precisely where judgment is needed. This is cheaper (the human reviews fewer cases), faster (review happens at the decision point, not after the output), and more effective (human attention is concentrated on the cases most likely to contain errors).
Most enterprises deploying AI agents in 2026 have not made this architectural choice. They have deployed agents end-to-end and placed human reviewers at the output. The result is the worst of both worlds: they pay for AI inference and human review on every task, the humans spend their time checking routine cases rather than exercising judgment on hard ones, and the error rate on the genuinely ambiguous cases — the ones where judgment matters — is no better than it would be without AI.
Blind Spot 4: Augmentation Is Higher-ROI Than Replacement, and Nobody Is Modelling It
The AI replacement thesis is built on a headcount substitution model: one AI agent replaces one human employee, and the savings are the difference in their fully loaded costs. This is the model the Token Economy prices. It is also the lower-return deployment pattern.
The higher-return pattern is augmentation — deploying AI to handle the routine throughput of a role while the human redirects their time from busywork to the judgment-intensive, relationship-intensive, and creative work that the routine work was previously crowding out.
The economics of augmentation are different from the economics of replacement, and the difference is consequential. In replacement, the return is cost savings: $135,000 minus $82,000 equals $53,000 per year per role, minus transition costs. In augmentation, the return is revenue and quality uplift: the human employee whose 3.8 hours of daily busywork are eliminated can redirect that time — roughly 950 hours per year — to client relationship building, strategic problem-solving, process improvement, and the generation of new institutional knowledge.
The value of those 950 redirected hours depends entirely on the role and the individual. For a mid-level account manager maintaining a $2 million book of business, 950 additional hours of client-facing relationship work might improve retention by 5–10 percentage points, worth $100,000–$200,000 in preserved annual revenue. For a procurement specialist, 950 hours redirected from routine purchase orders to supplier relationship management and cost negotiation might yield $50,000–$150,000 in annual savings. These figures are illustrative, not benchmarks — the actual value will vary dramatically by role, industry, and individual capability.
The critical point is structural, not numerical: augmentation preserves the institutional knowledge and ingenuity of the human while eliminating the routine work that suppresses their value. Replacement captures the cost savings and destroys the knowledge. The replacement model appears on the spreadsheet as a clean cost reduction. The augmentation model appears as a productivity multiplier that is harder to measure but may be worth 2–4x the replacement savings in roles where institutional knowledge and relationship capital are significant.
The market is not modelling this because the replacement model is simpler, the savings are more visible, and the headcount reduction appeals to boards and investors in a way that “we made our existing employees more productive” does not. This is a failure of measurement, not a failure of economics.
Blind Spot 5: The Capability Frontier Is Moving — The Transition Risk Is What Kills You
Most analyses of human-vs-AI capabilities treat the current frontier as either permanent (”AI will never be creative”) or temporary (”AI will do everything within five years”). Both framings are wrong, and both are dangerous.
The honest assessment is that several capabilities are structurally difficult for probabilistic systems — generating genuine novelty rather than recombining existing patterns, navigating organizational politics, building relationship capital, exercising ethical judgment under uncertainty, and recognising that the metrics being optimized are the wrong metrics. These capabilities are difficult for AI not because of insufficient training data or compute, but because they require embodied experience, real-world consequence, and the kind of contextual understanding that emerges from being a participant in a situation rather than an observer of its textual residue.
Whether these structural difficulties are permanent or temporary is an open question that this article will not pretend to answer. Multimodal AI, agentic systems with persistent memory, and models fine-tuned on organizational data are narrowing some of these gaps at a pace that has surprised even researchers. Five years ago, writing coherent prose and generating working code were on the “AI cannot do” list. They are no longer.
The strategic error is not in predicting the wrong future. It is in failing to account for the transition period. Even if AI eventually acquires every capability currently held by humans, the transition — the period between “AI cannot do this” and “AI can do this reliably at enterprise scale” — is where the damage occurs. During the transition, capabilities are partially automated: good enough to deploy, not good enough to trust without supervision. Organizations that replace humans based on a capability that is 80% there will discover that the missing 20% was the 20% that mattered — the edge cases, the exceptions, the situations where the difference between a correct and incorrect response is not pattern-matching but judgment.
The correct posture is not to bet on the frontier holding or collapsing. It is to design deployments that are robust to either outcome. This means building architectures that allow humans to be reinserted when AI capabilities prove insufficient, preserving the institutional knowledge that would be needed if the AI system fails, and maintaining a human workforce with the contextual depth to supervise AI systems through the capability transitions that will inevitably occur over the next 3–5 years. It means treating the replacement decision as reversible in design, even if the intent is for it to be permanent.
The enterprise that fires thirty knowledge workers on the assumption that AI capabilities will continue to improve is making an irreversible bet on a reversible trajectory. The institutional knowledge those workers hold cannot be re-hired. Once it leaves, the cost of reconstructing it — if it can be reconstructed at all — exceeds the cost of having preserved it.
The Question the Spreadsheet Cannot Answer
The Token Economy asks: what does a knowledge worker cost in tokens? The answer is precise and useful.
This article asks a different question: what does the organisation lose when the knowledge worker leaves? That answer is imprecise, context-dependent, and impossible to reduce to a single number. It is also the answer that determines whether the AI deployment compounds in capability over time or decays into an expensive system that your remaining employees spend their days correcting.
The five blind spots described above are not arguments against AI deployment. They are arguments against the particular form of AI deployment that the market’s current analytical framework encourages: the headcount-substitution model, executed without architectural foundations, without a knowledge-generation workforce, without the probabilistic-deterministic boundary, and without the humility to acknowledge that the capabilities AI lacks today may be the capabilities that mattered most.
The enterprises that navigate this correctly will not be the ones that deploy the most agents or eliminate the most headcount. They will be the ones that build the Context Layer before they deploy the agents, that staff the knowledge-generation function before they replace the knowledge workers, that place human review at the confidence boundary rather than at the output, and that model the augmentation returns alongside the replacement savings.
The spreadsheet will tell you the AI agent costs $82,000 and the human costs $135,000. It will not tell you that the human was the reason the AI agent worked at all — and that removing her is the first step toward the AI system’s obsolescence.
This article is the second in a series on AI transformation economics. The first — The Token Economy — presents the fully loaded cost model. The architectural framework referenced here is detailed in The Modern AI Construct.