

The Vibe Coding Illusion: Why Faster Code Is Not Faster Software
Companies adopted AI code generation expecting a step-change in delivery speed. What they got instead was a step-change in backlog size.

The numbers look extraordinary on paper. Ninety-two per cent of American developers now use AI coding tools daily. GitHub reports that 46% of all new code is AI-generated. Median task completion times have dropped 20–45% for greenfield features. And yet, a SmartBear survey released in March 2026 found that 70% of software leaders say application quality has already degraded as AI accelerates development. The 2024 DORA report — the gold standard for delivery metrics — found that a 25% increase in AI adoption correlated with a 7.2% decrease in delivery stability and a 1.5% decrease in throughput. Something does not add up.
The explanation is not complicated, but it requires abandoning a comforting fiction: that software delivery speed is determined by how fast you write code. It is not, and it never was. Writing code has not been the binding constraint on enterprise software delivery for decades. The binding constraints live downstream — in review, in testing, in validation, in release coordination, in production operations. Vibe coding did not remove those constraints. It simply moved the flood of work-in-progress upstream of them, faster than anyone anticipated.
The metaphor is a four-lane highway that feeds into a single-lane bridge. Widening the highway to eight lanes does not get more cars across the river. It creates a longer traffic jam on the approach.
The Bottleneck Cascade
To understand why companies are not seeing the promised returns, it helps to walk through the software delivery pipeline stage by stage, tracing where the pressure accumulates when code generation speed doubles or triples.
1. Pull Request Review
This is the most immediate and best-documented casualty. Telemetry from over 10,000 developers across 1,255 teams shows that AI-enabled developers merge 98% more pull requests — but PR review times increase by 91%. The reasons are structural. AI-generated code produces larger pull requests with unfamiliar patterns. Reviewers must verify logic they did not write, against intent they did not formulate. The cognitive load per review rises at the same time that the volume of reviews doubles. The result is a queue that grows faster than it drains. PRs sit in review for days. Developers context-switch to other work while waiting. Merge conflicts accumulate. What was meant to be a speed-up becomes a coordination tax.
2. Quality Assurance and Testing
The SmartBear survey is unambiguous: 68% of software leaders expect faster AI development to create testing bottlenecks. Almost 60% of teams still perform more than 40% of their application testing manually. When code output doubles, QA teams face a binary choice: test at the same depth and fall behind, or test at reduced depth and let defects through. Most choose a messy middle — partial coverage, longer cycles, rising escape rates. The GitLab Global DevSecOps Report 2025 found that teams lose an average of seven hours per week to AI-related inefficiencies, with verification identified as the primary culprit. GitLab calls this the “AI Paradox”: the ability to generate code has outpaced the ability to verify it.
3. User Acceptance Testing (UAT)
If QA is overwhelmed, UAT becomes catastrophic. Business stakeholders tasked with validating features are not engineers. They cannot absorb a tripling of test scenarios without a proportional increase in time, headcount, or tooling — none of which typically materialises. The result is either rubber-stamped UAT (which defeats its purpose) or UAT that becomes the longest phase in the cycle, stretching release timelines past what they were before vibe coding was adopted. Either outcome erases the upstream gains.
4. Security Review
AI-generated code introduces a specific and well-documented security risk profile. The Lovable vulnerability incident — in which 10.3% of AI-generated apps had critical row-level security flaws — is illustrative, not exceptional. Sonar’s State of Code report found that 96% of developers do not fully trust AI code accuracy, yet only 48% verify it. Security teams that were already understaffed relative to human-authored code volume are now expected to review code that is more voluminous, less predictable in structure, and generated by developers who may not fully understand what they shipped. The security review stage becomes either a bottleneck that blocks releases or a gap that lets vulnerabilities through. Neither is acceptable.
5. Architecture and Design Review
Vibe coding optimises for local correctness — this function works, this endpoint returns the right data. It does not optimise for systemic coherence. When multiple developers (or agents) independently generate solutions to adjacent problems, the resulting codebase can drift toward architectural inconsistency: duplicated logic, conflicting patterns, misaligned data models. Architecture review, traditionally a lightweight gate, becomes a heavyweight intervention as reviewers must reconcile divergent approaches that all technically work in isolation but fail to compose. Decision latency — the deferral of key design choices about interfaces, invariants, failure modes, and security boundaries — compounds with every AI-generated commit that skips the upfront design step.
6. CI/CD Pipeline Congestion
Continuous integration systems have finite compute budgets and finite parallelism. A doubling of merged code means a doubling of build and test runs. Pipelines that ran in 20 minutes begin running in 45. Queues form. Developers wait for green builds. Flaky tests, already a nuisance, become a crisis when they block twice as many pipelines per day. Infrastructure teams that sized their CI/CD environments for human-speed development find themselves over capacity without having hired anyone new.
7. Documentation and Knowledge Transfer
AI-generated code is frequently underdocumented or documented in a generic, unhelpful way. When code is written faster than teams can absorb its intent, institutional knowledge fragments. New team members onboarding into a codebase that is 40–60% AI-generated face a comprehension problem that no README addresses: the code works, but nobody on the team can explain why specific decisions were made. This “comprehension debt” — a term gaining traction in enterprise circles — does not surface as a bottleneck immediately. It surfaces six months later, when the team tries to modify, extend, or debug code that nobody fully understood in the first place.
8. Release Management and Change Control
Regulated industries — finance, healthcare, government — operate under change control regimes that require human sign-off, audit trails, and documented rationale for every production change. These regimes were designed for a cadence of dozens of changes per sprint, not hundreds. Vibe coding does not change the regulatory requirement. It simply generates more work for the same number of change advisory board members, compliance officers, and release managers. The bottleneck is not technical. It is procedural and, in many cases, legally mandated.
9. Production Incident Response
The 2024 DORA report’s finding that AI adoption correlates with decreased delivery stability is not an accident. More code, reviewed less thoroughly, tested less completely, and released more frequently produces more production incidents. Incident response teams — already operating at capacity in most organisations — face increased volume without increased staffing. Mean time to resolution (MTTR) degrades because debugging AI-generated code that the on-call engineer did not write, in patterns they do not recognise, takes longer than debugging familiar human-authored code.
10. Cross-Team Dependencies and Coordination
Enterprise software is rarely built by a single team. Features routinely span frontend, backend, platform, and data teams. When one team accelerates via vibe coding and its dependencies do not, the faster team simply generates more work-in-progress that blocks on the slower team’s capacity. Amdahl’s Law applies ruthlessly: the overall speed of a system is limited by its slowest sequential component. AI-enabled parallelism within a single team does not help when the constraint is a shared service team that reviews API contracts manually.
11. Technical Debt Accumulation
Seventy-six per cent of developers surveyed by Sonar believe AI-generated code requires refactoring. AI adoption was associated with a 154% increase in average PR size and a 9% increase in bugs per developer across a large-scale telemetry study. Code that ships fast but requires refactoring later is not free. It is debt with a deferred interest payment. Organisations that celebrate the velocity gains of vibe coding without accounting for the remediation costs downstream are engaging in a form of accounting fraud against their own engineering capacity.
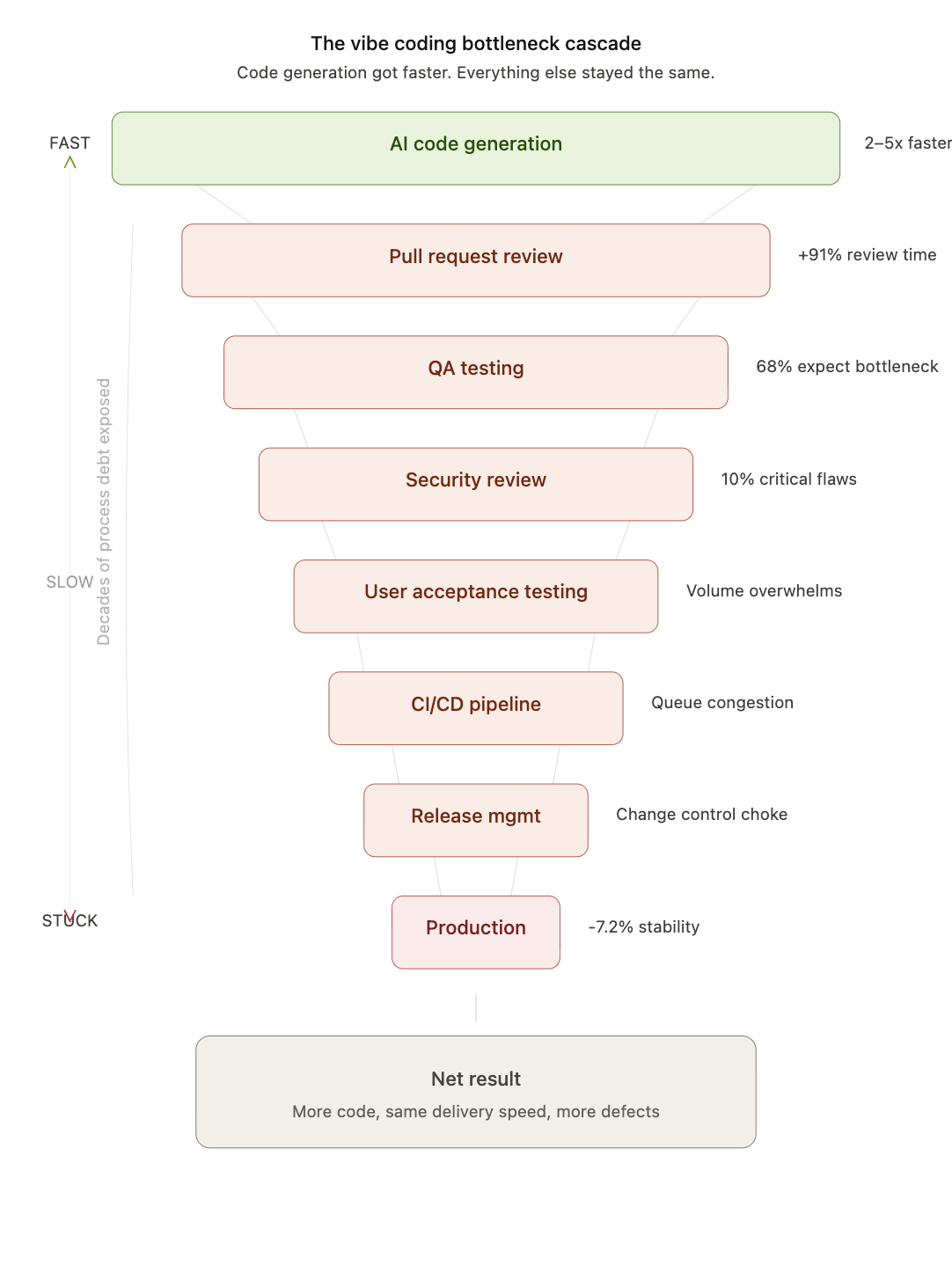
The Root Cause: Process Debt
The paper “Revenge of QA,” published in the Fall 2025 Enterprise Technology Leadership Journal, frames the problem precisely. AI is not creating new problems. It is exposing decades of process debt that was previously masked by the fact that code generation was slow enough to let downstream stages keep pace. Organisations that invested in quality gates, approval processes, and manual testing over the years built machinery designed for a different era — one in which code generation was the bottleneck. That era ended. The machinery did not adapt.
The fundamental error is treating vibe coding as a tool upgrade when it is actually a systems problem. Buying a faster engine for a car with worn brake pads does not make the car faster. It makes the car dangerous.
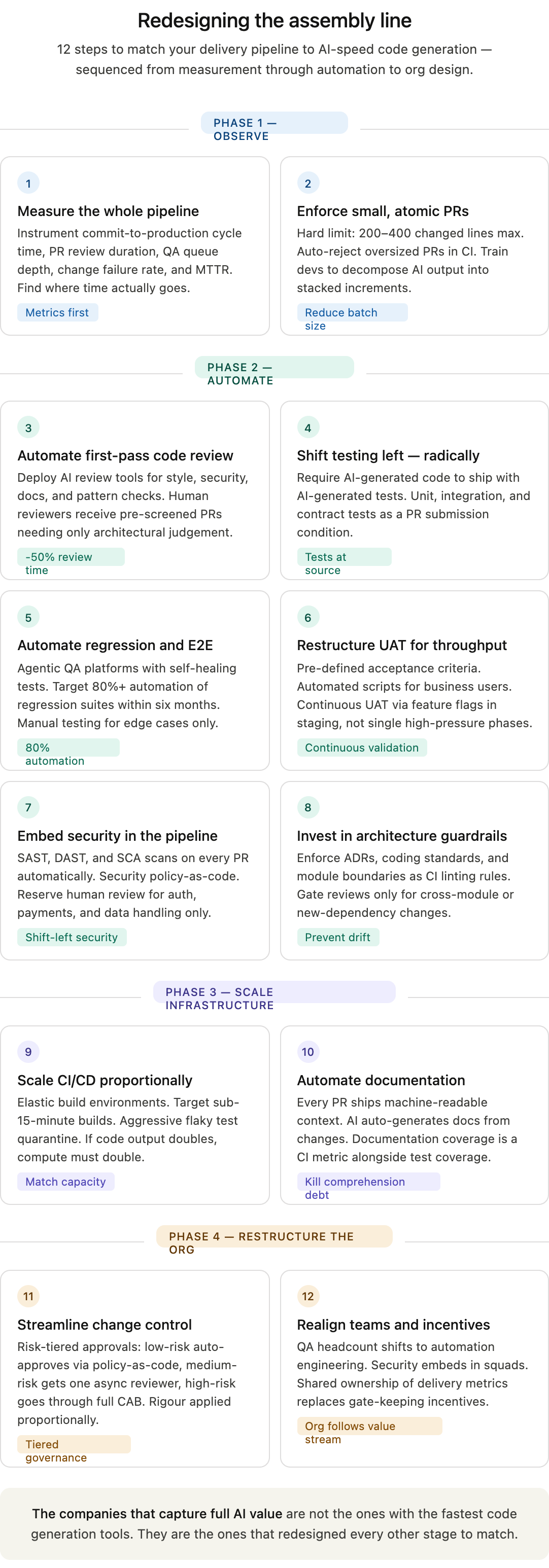
The Fix: Redesigning the Assembly Line
The solution is not to slow down code generation. It is to accelerate, automate, and restructure every other stage of the delivery pipeline to match the new throughput. This requires process re-engineering, not tool shopping.
Step-by-Step Guide: Retooling the Software Delivery Pipeline for AI-Speed Development
Step 1: Measure the Whole Pipeline, Not Just Coding Speed
Before changing anything, instrument the full delivery cycle from commit to production. Track cycle time, PR review duration, QA queue depth, UAT turnaround, deployment frequency, change failure rate, and MTTR. Most organisations celebrating vibe coding gains are measuring only coding speed. The first step is to see where time actually goes. The data will reveal the bottlenecks — typically review, testing, and release coordination — with precision.
Step 2: Enforce Small, Atomic Pull Requests
AI tools encourage large, sprawling PRs because generating code is cheap. This is the single most destructive habit to permit. Establish hard limits on PR size — 200–400 lines of changed code maximum. Configure CI to reject oversized PRs automatically. Train developers to decompose AI-generated output into stacked, reviewable increments. Smaller PRs review faster, merge faster, and produce fewer conflicts. The upstream cost of decomposition is vastly lower than the downstream cost of review congestion.
Step 3: Automate First-Pass Code Review
Deploy AI-assisted code review tools (Qodo, CodeRabbit, Graphite, or equivalent) to handle the first pass: style enforcement, security scanning, documentation checks, and pattern consistency. Human reviewers should receive PRs that have already passed automated gates and require only architectural judgement and business logic validation. This reduces human review time per PR by 30–50% and redirects human attention to where it has the highest marginal value.
Step 4: Shift Testing Left — Radically
The traditional model of “developers write, QA tests” is incompatible with AI-speed development. Testing must move into the development phase itself. Require AI-generated code to arrive with AI-generated tests — unit tests, integration tests, and contract tests — as a condition of PR submission. Use AI testing tools to auto-generate test cases from requirements or user stories. The goal is that by the time a PR reaches QA, the basic correctness questions have already been answered. QA’s role shifts from “does it work?” to “does it work correctly in the system context?” — a higher-value, lower-volume activity.
Step 5: Automate Regression and E2E Testing
Manual regression testing at scale is untenable. Invest in agentic QA platforms that generate and maintain end-to-end tests from natural language descriptions or recorded user flows. Self-healing test frameworks — those that adapt automatically when UI elements change — eliminate the maintenance burden that makes traditional automation brittle. Target 80%+ automation of regression suites within six months. The remaining manual testing should focus exclusively on exploratory testing and edge cases where human judgement is irreplaceable.
Step 6: Restructure UAT for Throughput
UAT cannot remain an unstructured, business-stakeholder-driven phase when feature volume triples. Implement structured UAT protocols: pre-defined acceptance criteria linked to user stories, automated test scripts that business users can execute without technical skill, and time-boxed UAT windows with clear escalation paths for failures. Consider “continuous UAT” models where business validation happens incrementally against feature flags in staging environments, rather than in a single high-pressure phase before release.
Step 7: Embed Security in the Pipeline, Not After It
Security review as a gate after development is a bottleneck by design. Integrate static analysis (SAST), dynamic analysis (DAST), and software composition analysis (SCA) directly into CI/CD. Every PR should be scanned automatically before it reaches a human reviewer. Establish a security policy-as-code framework so that common vulnerability patterns are caught programmatically. Reserve human security review for high-risk changes: authentication, authorisation, payment processing, data handling. Everything else should pass or fail automatically.
Step 8: Invest in Architecture Guardrails
Prevent architectural drift before it starts. Define and enforce architectural decision records (ADRs), coding standards, and module boundaries as linting rules and CI checks. Use AI tools that validate generated code against your existing patterns and flag deviations. Designate architecture review as a required gate only for changes that cross module boundaries or introduce new dependencies. Intra-module changes that conform to established patterns should flow through without architectural hold-up.
Step 9: Scale CI/CD Infrastructure Proportionally
If code output doubles, CI/CD capacity must double. This is an infrastructure investment, not an optimisation problem. Provision elastic build environments that scale with queue depth. Prioritise pipeline speed: target sub-15-minute builds for the critical path. Invest aggressively in flaky test detection and quarantine. A flaky test that blocks one pipeline a day was annoying. A flaky test that blocks ten pipelines a day is an organisational emergency.
Step 10: Automate Documentation as a Build Artifact
Require every PR to include machine-readable context: what problem it solves, what design choices were made, what alternatives were rejected. Use AI to auto-generate documentation from code changes and commit history. Treat documentation coverage as a CI metric alongside test coverage. The goal is to make the codebase self-explaining so that comprehension debt does not accumulate silently.
Step 11: Streamline Change Control for AI Cadence
For regulated environments, work with compliance teams to redesign change control for higher throughput. Categorise changes by risk tier. Low-risk changes (cosmetic, configuration, well-tested internal tools) should auto-approve through policy-as-code. Medium-risk changes require asynchronous review by a single approver. Only high-risk changes (security boundaries, data schemas, external integrations) should go through full change advisory board review. This is not about reducing rigour. It is about applying rigour proportionally.
Step 12: Realign Team Structures and Incentives
The bottleneck problem is ultimately an organisational problem. Teams structured around the assumption that coding is slow will not function when coding is fast. QA teams need headcount reallocation toward automation engineering. Security teams need embedded representation in product squads rather than operating as a centralised gate. Release management needs automation, not more coordinators. Incentive structures that reward blocking (”not my job if it breaks”) must be replaced with shared ownership of delivery metrics across the full pipeline. The org chart must follow the value stream, not the other way around.
The Core Insight
Vibe coding works. The tools are genuinely capable. The productivity gains at the individual developer level are real. But individual productivity and organisational throughput are different things entirely. The companies that will capture the full value of AI-assisted development are not the ones that adopted the fastest code generation tools. They are the ones that recognised, early, that faster code generation is a forcing function for process re-engineering — and then actually did the re-engineering.
The rest will generate more code, ship at the same speed, accumulate more debt, and wonder why the revolution feels so underwhelming.