

How business leaders should think about enterprise AI architecture — and the conversations to have with your IT team
You are buying capabilities without building foundations. Here is what that costs you — and how to fix it.

There is a particular kind of meeting happening in boardrooms across the world right now. A technology vendor has just finished a demonstration. The AI system answered questions fluently, synthesised documents in seconds, flagged anomalies that would have taken a human analyst three days to find. The executives in the room are impressed. Someone says: we need this. A budget is approved. A project kicks off.
Twelve months later, the same executives are sitting in a different kind of meeting. The system works — technically. You cant quite tell if it actually works. It does not quite know the business. Its outputs are plausible but generic. It cannot access half the data it needs. Nobody is quite sure what it is actually doing, or why. The return on investment calculation, which looked obvious in the vendor demo, has become difficult to construct. A senior leader asks whether the organisation should simply have waited for better technology.
The problem is not the technology. The problem is architecture — or rather, the absence of it.
The organisations that are extracting genuine, compounding value from AI are not, for the most part, the ones that moved fastest or spent the most. They are the ones that built most deliberately. They thought, before deploying a single agent or signing a single platform contract, about how the components of an AI system relate to each other, what each requires from the others, and in what order investments need to be made for the whole to add up to something coherent.
Most organisations have not done this thinking. They have deployed AI the way companies once deployed early enterprise software: bottom-up, department by department, use case by use case, with the integration problem deferred to a future that always seems to remain just out of reach. The result, as it was with enterprise software in the 1990s, is a fragmented landscape of expensive tools that partially overlap, cannot talk to each other, and collectively fail to deliver anything approaching the vision that justified the original investment.
This article is about the framework that changes that calculation. It is a way of thinking — a mental model for understanding how the components of an future state enterprise AI system relate to each other, and what that implies for how investment should be sequenced, governed, and improved over time.
The Three Failure Modes
Before describing what good architecture looks like, it is worth being precise about how the absence of it manifests. There are three failure modes, and they are not independent. They compound each other.
The foundation failure is the most common and the least visible. It happens when organisations deploy AI agents — systems capable of autonomous action — on top of data infrastructure that was never designed for AI consumption. Every AI system is only as good as the context it can access. The large language models at the heart of modern AI are extraordinarily capable in the abstract; in practice, their outputs are shaped almost entirely by what they know about the specific situation they are being asked to address. An AI agent operating on rich, well-structured, current, enterprise-specific data will consistently outperform a more sophisticated model operating on impoverished information.
The problem is that most organisations’ data infrastructure was designed for a fundamentally different pattern of consumption. Traditional business intelligence consumed data periodically — weekly reports, monthly dashboards, quarterly reviews. AI systems consume data continuously, in real time, at high volume, with low latency. They need to access information across organisational silos that were never designed to communicate with each other. They are sensitive to data quality in ways that human analysts — who apply judgment, notice anomalies, and ask follow-up questions — are not. Bad data in a reporting environment produces a misleading chart, which a thoughtful analyst might question. Bad data in an agentic environment produces a cascade of wrong decisions, each reinforcing the last, none of them flagged until the damage is done.
The coordination failure becomes visible later, as AI adoption deepens. A single AI agent is manageable. A population of agents — each specialised for a different domain, each taking autonomous actions, each operating on overlapping and sometimes conflicting information — creates an orchestration challenge that most organisations are not thinking about until they are already in the middle of it.
Agents that are not coordinated duplicate effort. They make decisions that are individually reasonable but collectively incoherent — the customer service agent that offers a discount on the same day the pricing agent has flagged that margins are under pressure. They produce outputs that cannot be reconciled with each other because they drew on different versions of the same underlying data. And because nobody has a clear picture of what the agent population as a whole is doing, these problems compound silently. The error is not in any single agent. It is in the system.
The oversight failure is the most consequential and, in hindsight, the most avoidable. Automated systems make mistakes. This is not a criticism; it is a design reality that applies equally to human systems. The question is not whether an AI system will produce an error, but whether the organisation has designed itself to catch that error before it becomes expensive. Organisations that treat human oversight as a compliance afterthought — something to be added once the real work is done, a checkbox rather than a design constraint — consistently find that errors surface as costly failures rather than as recoverable learning opportunities.
The striking thing about these three failure modes is that they are all architectural problems. They are not problems of model quality, or of prompt engineering, or of any of the technical details that tend to absorb the attention of technology teams. They are problems of how the components of an AI system are assembled and governed. And they are all foreseeable — which means they are all preventable, for organisations that are willing to think about architecture before they build.
The Five Layers
The Modern AI Construct organises enterprise AI into a stack of five layers, moving from raw data at the foundation to user-facing interfaces at the top. The layering is not arbitrary. It reflects genuine dependency relationships: each layer’s performance constrains and enables the layer above it. Understanding the layers, and the order of their dependency, is the foundation of sound AI investment strategy.
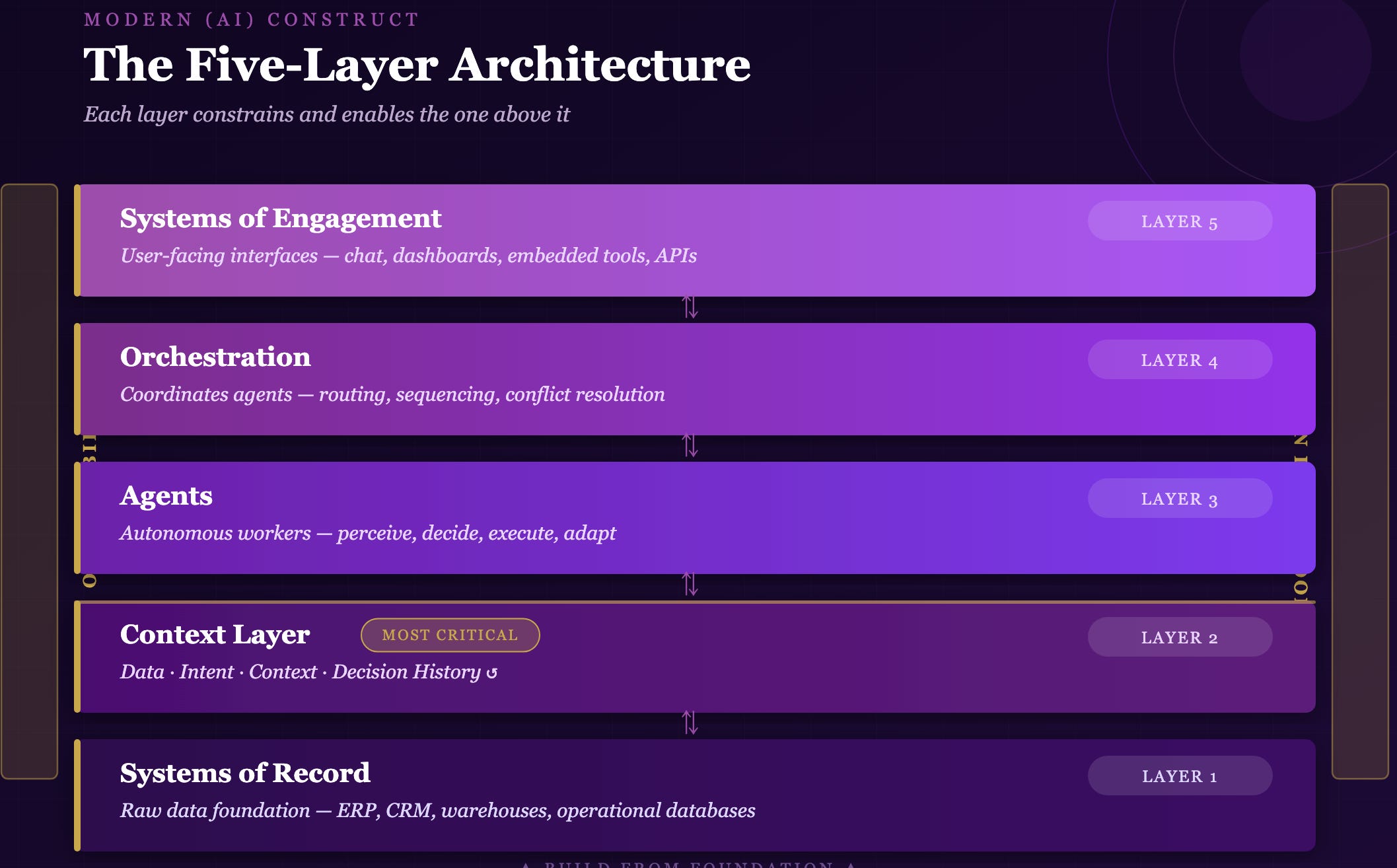
Systems of Record: The Foundation
At the base of the stack sits everything an organisation already knows. Systems of Record are the raw data layer — every ERP, CRM, data warehouse, operational database, file store, and authoritative information system the organisation maintains. This layer is not new. Every organisation has one. The question is whether it is ready for what AI demands of it.
The answer, in most organisations, is: not yet.
This is not because organisations have neglected their data infrastructure. Many have invested heavily in it, and with good reason. But the investment was optimised for a different purpose. Periodic consumption by human analysts is a fundamentally different problem from continuous consumption by AI agents. The data quality standards sufficient for a monthly management report are not sufficient for an agent making hundreds of decisions per day on behalf of the business. The access latency acceptable for a quarterly planning process is not acceptable for a real-time customer service agent.
There is also a structural issue that goes beyond quality and latency. Most organisations’ data infrastructure reflects the organisational structure that built it: siloed by department, by function, by the historical accidents of which software was procured when. Customer data lives in one system, financial data in another, operational data in a third, and the connections between them exist primarily in the minds of analysts who have learned, over years, how to navigate the landscape. AI agents do not have those years of accumulated context. They need the connections to be explicit, structured, and accessible.
The Context Layer: Where AI Becomes Intelligent
The Context Layer is the most misunderstood component of the framework, and the most strategically important. It sits above the raw data of Systems of Record and provides AI agents with everything they need to produce relevant, accurate, enterprise-specific outputs rather than generic responses. It is the difference between an AI system that knows your business and one that merely knows about business in the abstract.
The layer has four components that work together. The first is data in its curated form — not raw records, but processed, structured, semantically enriched information that an AI agent can consume efficiently and interpret accurately. The second is intent: not just what a user asked for, but what they are actually trying to achieve. The distinction matters more than it might appear. A request for a market analysis from a CFO preparing for a board meeting has different implicit requirements than the same request from a junior analyst doing exploratory research, even if the words are identical. Systems that cannot capture intent produce outputs that are technically responsive but practically useless.
The third component is context in the situational sense — who is asking, from which department, in which business process, at what stage of a workflow, with what constraints. An AI agent operating in a regulated environment needs to know which outputs are subject to compliance review. An agent supporting a sales process needs to know where in the cycle a particular deal sits. Context of this kind is rarely explicit in a user’s request; it must be inferred from a rich ambient understanding of the organisational environment.
The fourth component is Decision History — a record of past decisions and their outcomes, fed back in as input rather than generated here. This feedback loop is what allows an enterprise AI system to learn from experience. Organisations that design their Context Layer without this feedback mechanism build systems that are fundamentally stateless: every session starts from the same place, the system never improves from its own history, and the gap between its outputs and what the business actually needs never closes.
Addtional reading: How contexts fail and how to fix them
Agents: The Workers
Agents are AI systems that take actions. They are the most visible part of the stack because they are the part that actually does things — and it is important to be precise about what distinguishes an agent from a simpler AI system.
A model, in the technical sense, responds when prompted. An agent perceives a situation, determines what to do, executes a sequence of actions, and delivers a result. The autonomy is real, which is what makes agents powerful and what makes their governance non-trivial.
There is, however, a property of agents that most business leaders deploying them do not fully appreciate, and it has significant architectural consequences. AI agents built on large language models are fundamentally probabilistic systems. They do not compute a single correct answer. They sample from a distribution of plausible answers. The same input, in a strict sense, does not guarantee the same output. This is not a bug — it is what makes them capable of handling ambiguity and reasoning across unstructured information. But it is a fundamental statement about the kind of truth claim they are making. And it means that wherever agent outputs feed into downstream processes that require consistency, correctness, or auditability, the architecture must explicitly manage the transition from probabilistic inference to deterministic execution. This distinction is explored further below, because getting it wrong is the source of failures that the five-layer framework alone does not fully explain.
Orchestration: The Coordinator
Orchestration is perhaps the most underappreciated layer in the framework. It is the component that makes a collection of agents into a coherent system — managing how they work together, routing tasks to the appropriate agent, sequencing workflows that span multiple agents, detecting and resolving conflicts, and ensuring that complex processes complete in a way that makes sense from end to end.
The analogy that captures it best is air traffic control. Individual aircraft are capable, autonomous, and operated by skilled professionals. The air traffic control system does not make the aircraft more capable. What it does is ensure that all of them can operate simultaneously without catastrophic interference, that handoffs happen safely, and that the overall flow of traffic is optimised rather than simply the immediate priorities of each individual flight.
The characteristic mistake organisations make with orchestration is to treat it as something that can be added later — once they have built enough agents to clearly need it. This is precisely backwards. Retrofitting an orchestration layer onto an existing population of agents is expensive and disruptive, because the agents were not designed with the orchestration layer in mind. The right moment to think about orchestration is before the first agent goes into production.
Systems of Engagement: The Interface
Systems of Engagement are what users see — conversational interfaces, analytical dashboards, embedded AI capabilities within existing applications, APIs that allow other systems to consume AI outputs. They are the most visible part of the stack and, for that reason, the part that receives the most organisational attention.
The quality of any System of Engagement is almost entirely determined by the layers beneath it. A polished conversational interface sitting on top of a poorly designed Context Layer and ungoverned agents will produce outputs that look impressive in a demo and disappoint in daily use. Organisations should resist the instinct to start with the interface before the underlying architecture is ready to support it. Conversely, an organisation with a strong foundation can improve its user experience at relatively low cost — the intelligence is already there; it simply needs a better window.
The Distinction Most Organisations Are Getting Wrong
There is a deeper architectural error running through every layer of the stack that the framework alone does not surface — one that is causing real production failures and that most organisations will not encounter until they have already paid for the lesson.
A deterministic system produces the same output for the same input, every time. A probabilistic system produces outputs drawn from a distribution — the same input may yield different outputs across runs. This is not merely a technical property; it is a fundamental statement about what kind of truth claim the system is making. Deterministic systems assert: this is the answer. Probabilistic systems assert: this is a likely answer.
AI agents built on large language models are, by architecture, probabilistic. The problem is that organisations are deploying them in contexts that have zero tolerance for output variance.
Finance and legal teams are running compliance and audit workflows through LLM-based classifiers — processes legally required to be consistent and reproducible, where reviewing the same document twice must yield the same classification. Data engineering teams are routing ETL processes, field mapping, and schema conversion through models, where a regex or lookup table would be faster and more reliable. Financial reporting tools are being built on models that are demonstrably unreliable at precise computation. Form validation tasks with a single correct answer — extract this account number, identify this diagnosis code — are being handled by systems with no deterministic validation layer downstream. Routing and orchestration logic — deciding which function to call, which policy applies — is being handed to inference engines when it is, properly understood, a decision tree.
Three dynamics drive this misapplication. First, LLMs are genuinely impressive at unstructured tasks, which creates a hammer-nail effect: teams with LLM capability reach for it even when the problem is structured. Second, probabilistic failures feel correct most of the time in testing, masking failure modes that only surface at scale or in edge cases. A rule engine that fails is obviously broken. An LLM that confidently gives a wrong answer looks, in every observable way, like it is working. Third, there is organisational incentive to deploy “AI” solutions, which biases teams toward probabilistic models even when deterministic alternatives are more appropriate.
The right question is not “deterministic or probabilistic?” but something sharper: does this problem have a closed-form correct answer, and is the cost of a wrong answer asymmetric? If yes to both, determinism is not a preference — it is a requirement. Probabilistic systems are appropriate where the problem space is open-ended, where outputs require judgment over lookup, or where the distribution of acceptable answers is wide: natural language generation, semantic search, summarisation, synthesis across ambiguous inputs. Rule application, calculation, format validation, schema transformation, state machine transitions, access control decisions, audit logging — anything legally or contractually required to be reproducible — belongs in deterministic systems.
The Compounding Failure
The real damage is not individual misapplications but architectural compounding. When probabilistic outputs feed downstream deterministic processes — an LLM extraction feeding a rule-based compliance engine, for instance — the variance at the probabilistic layer becomes systemic brittleness at the deterministic layer. The deterministic system assumes clean, consistent inputs. The probabilistic upstream cannot guarantee them. The failure mode is invisible until it is not.
This is the precise mechanism behind a pattern organisations encounter repeatedly: the AI system appears to work correctly through testing, performs adequately at low volume, and then produces a wave of silent errors at scale that nobody can explain, trace, or reproduce consistently. The problem is not model degradation. The problem is that the architecture never separated the interpretation problem from the execution problem, and the long tail of edge cases where the probabilistic system makes a wrong call is now large enough to matter.
Every system that processes real-world inputs faces these two distinct problems. The interpretation problem: the world is messy, language is ambiguous, inputs are incomplete or inconsistently formatted, and intent is not always explicit. The execution problem: once meaning is established, actions must be taken correctly, consistently, and auditably. These require fundamentally different computational properties. Probabilistic systems are well-suited to the interpretation problem because ambiguity is intrinsic to it. Deterministic systems are required for the execution problem because correctness is binary — an account is debited or it is not, a rule is applied or it is not. Conflating these two problems by using a single probabilistic system end-to-end is the root error.
The Correct Pattern
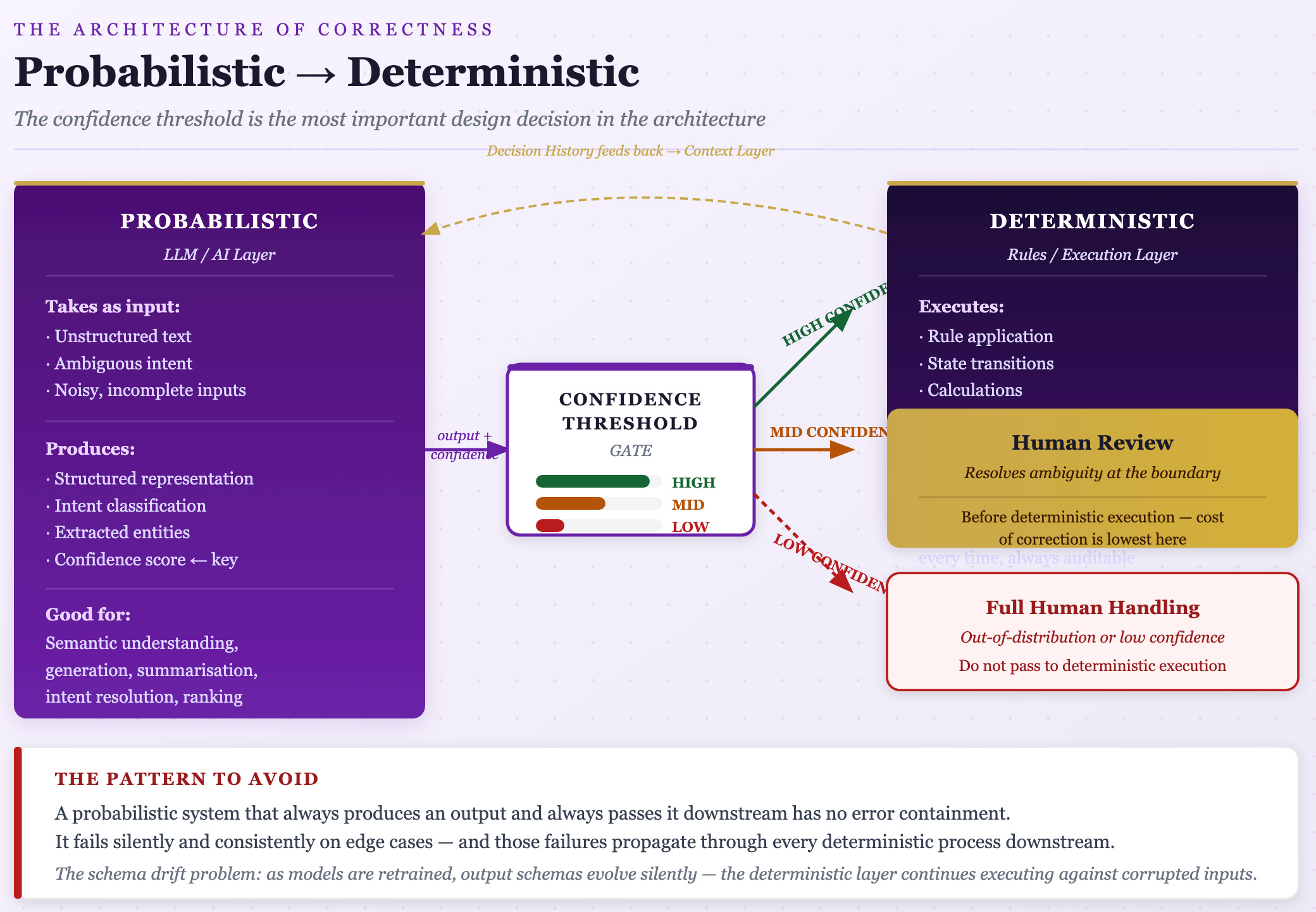
The architecturally sound design places a probabilistic layer that handles ambiguity upstream of a deterministic layer that enforces correctness constraints. The probabilistic layer’s job is to reduce ambiguity to a structured representation — it takes unstructured or semi-structured input and produces a structured output: an intent with a confidence score, a set of extracted entities, a classified category, a resolved reference. That output is not a final answer. It is a claim about meaning, accompanied by a measure of uncertainty. The deterministic layer’s job begins where the probabilistic layer’s job ends: it receives the structured representation and applies rules, constraints, and logic against it. It does not interpret — it executes.
The boundary between these layers is the most important design decision in the architecture. It must be explicit, typed, and validated. If the deterministic layer has to guess what the probabilistic layer meant, the boundary has failed.
This pattern has precedent in compiler design. A compiler’s front end takes raw source text and resolves it into an abstract syntax tree — a structured, unambiguous representation of meaning. The back end operates deterministically on that structured representation. No compiler designer would suggest that the back end should also read raw source text and infer what the programmer meant. The separation is obvious because the failure modes of doing otherwise are obvious. The same separation should be obvious in AI system design — but because LLMs feel capable of doing everything, the architectural discipline that compiler designers take for granted has not become standard practice in AI engineering.
The practical mechanism governing this architecture is the confidence threshold. A well-designed system does not pass probabilistic outputs downstream regardless of confidence. High confidence above a defined threshold routes to straight-through deterministic processing. Medium confidence routes to a review queue. Low confidence routes to full human handling. This is not optional — it is the mechanism by which the architecture maintains correctness guarantees. A probabilistic system that always produces an output and always passes it downstream has no error containment. It fails silently and consistently on edge cases, and those failures propagate through every deterministic process downstream.
There is also a schema drift problem that organisations consistently underestimate. As models are retrained or swapped, the output schema of the probabilistic layer evolves. The deterministic layer’s input assumptions break — but unlike a traditional API contract failure, which throws a visible error, schema drift in an LLM output often produces something that parses correctly but means something different. The deterministic system continues executing against corrupted inputs. Without explicit, typed, validated boundaries between the layers, this failure mode is not a risk. It is a certainty over any reasonable deployment horizon.
The Two Cross-Cutting Concerns
Two capabilities in the framework do not sit within a single layer. They must run through all five, which is what makes them easy to defer and expensive to neglect.
Observability
Observability, in the context of AI systems, means something considerably richer than its equivalent in traditional software. In conventional engineering, observability means monitoring uptime, error rates, and performance metrics. In an AI system, it means understanding what the system is actually doing, why it is doing it, and whether it is producing good outcomes.
This distinction matters because AI systems fail in ways that traditional monitoring does not detect. An AI agent can be running perfectly, producing outputs at normal speed with no technical errors, while simultaneously making decisions that are systematically wrong in ways that take months to surface. The output of an AI system is not a binary pass/fail; it is a judgment call, and the question of whether that judgment is good is not one that error rate metrics can answer.
Real observability means being able to trace any output back to the data that influenced it, understand why an agent chose a particular course of action, detect when agent behaviour is drifting before that drift produces visible failures, and measure, at the level of business outcomes, whether the system is actually working.
Observability must be designed into the architecture from the beginning. This is not a matter of adding monitoring dashboards later; it is a matter of designing every layer so that its behaviour is visible and interpretable. Retrofitting it requires rebuilding significant parts of everything above it.
Human in the Loop
Human in the Loop is the most frequently misunderstood concept in AI governance. It does not mean that a human must approve every AI action. The correct interpretation is more precise: every AI system should have a designed human role, and the level of human involvement should be calibrated to the risk and reversibility of the actions being taken.
But the question of where in the architecture humans are placed is as important as whether they are placed there — and most organisations get this wrong. The instinct is to place human review at the output of the system, after the deterministic layer has executed. By that point the cost of reversal is high. Records have been written, commitments may have been made.
The correct placement is at the confidence threshold boundary, between the probabilistic and deterministic layers, before execution. This is when the cost of correction is minimal. The human’s job is not to review a finished output but to resolve an ambiguity the probabilistic system could not resolve reliably. Once they do, the deterministic layer executes against a human-validated structured input. This is exception-based review done correctly — it is the architecture that allows automation rates to be high on routine cases while maintaining correctness guarantees on the cases that actually matter. It also maps precisely onto the risk calibration argument: low-risk, easily reversible outputs from the probabilistic layer can pass to straight-through deterministic execution; high-risk outputs route to human review at the boundary.
Every organisation implementing AI should have a Human Oversight Policy that categorises decision types by risk level, specifies the required confidence threshold and human role for each category, and has been reviewed by legal and compliance functions. Architects need this policy before they design the workflows. If the oversight requirements are unclear, the architecture will make implicit choices — and implicit choices about risk are almost never the ones the organisation would make explicitly.
Why Investment Sequencing Is Strategy
Everything in the framework points to a single, non-obvious conclusion about investment sequencing: the layers that generate the most visible excitement — agents and interfaces — are not the layers where investment should begin. The layers that matter most are the unglamorous ones at the bottom.
Start with the Context Layer before deploying agents. Every agent is constrained by the quality of the context available to it. An agent with access to rich, well-structured, current, organisation-specific context will outperform a more sophisticated agent operating on impoverished data, every time. The difference between an AI system that genuinely knows the business and one that produces generic approximations is almost entirely a Context Layer problem.
Design for the agent population you will have in two years, not the one you have today. Orchestration infrastructure designed for two agents is not the same as orchestration infrastructure designed for twenty. The incremental cost of building for scale at the outset is modest. The cost of refactoring an under-engineered architecture while it is in production is substantial.
Define the probabilistic-deterministic boundary before writing the first line of agent code. For every workflow the organisation intends to automate, map which steps involve genuine ambiguity — the domain of probabilistic systems — and which steps involve executing rules, transformations, or calculations against established inputs. The boundary between them must be explicit, typed, and validated. Define the confidence thresholds governing routing at that boundary. Define what happens at each confidence band. This is not an implementation detail; it is the architectural decision that determines whether the system fails visibly or silently.
Treat observability as a first-class engineering requirement. Before any AI capability goes into production, the team responsible for it should be able to answer two questions concretely: how will we know when it is working, and how will we know when it has stopped working? If either answer is vague, the system is not ready.
Write the Human Oversight Policy before the architecture is designed, and locate human review at the probabilistic-deterministic boundary rather than at the system output. The level of oversight required for a given class of action shapes the workflows. If the policy does not exist when architects begin work, they will make implicit assumptions — almost always wrong ones.
Invest in the feedback culture, not just the feedback loop. The technical mechanism for feeding decision outcomes back into the Context Layer only generates useful signal if the organisation creates the conditions for it. This means training people to notice and report when AI outputs are wrong, capturing whether AI recommendations were acted upon and what happened as a result, and treating the analysis of AI performance as an ongoing discipline. Organisations that expect AI systems to improve themselves, without deliberate human investment in the feedback process, consistently find their systems stagnating.
The Conversation You Need to Have
None of this is primarily a technology problem. It is a leadership problem. The decisions that determine whether an organisation’s AI architecture will compound in value or fragment into expensive islands are not made by architects or engineers. They are made by business leaders who set investment priorities, define governance requirements, and create the organisational conditions for AI to work.
The most important conversation most organisations can have about AI right now is not with a vendor. It is with their own IT and architecture teams.
What does our Systems of Record layer actually look like — not the idealised version, but the honest one? How much of our data is locked in legacy systems, PDFs, and email threads? What is the real state of our data quality, assessed against the standard of autonomous AI consumption rather than human-interpreted reporting?
What is our Context Layer strategy? Do we have a knowledge architecture that connects information across organisational silos? What is our approach to decision logging, and does it create the feedback loop that makes AI systems learn from their own history?
Where have we drawn the probabilistic-deterministic boundary in our current AI deployments? Are LLMs being used for tasks that have closed-form correct answers — compliance classification, arithmetic, structured data extraction? Are there downstream deterministic processes relying on probabilistic outputs without typed, validated schemas between them? What are our confidence thresholds, and were they set by architects or by business pressure to maximise automation rates?
What is our agent governance model for the population we will have in two years? Do we have an orchestration layer, or are agent interactions currently point-to-point integrations that will not scale? Where, precisely, does human review occur — at the system output, or at the confidence threshold boundary before deterministic execution?
These are not comfortable questions. The honest answers, in most organisations, reveal significant gaps. But they are the right questions — and the organisations asking them now, rather than after the first expensive failure, are the ones that will have something to show for their AI investment in three years.
The Compounding Organisation
The most important property of a well-designed AI architecture is one that is almost impossible to demonstrate in a vendor demo: it compounds.
In an architecture built on these principles, each new agent makes the Context Layer richer. Every decision logged, every outcome recorded, every pattern extracted from the accumulating history of AI-assisted decisions adds to the foundation that makes the next agent more capable than the last. The Orchestration layer makes the whole system more capable than the sum of its parts. Observability makes improvement a systematic discipline. And a cleanly maintained probabilistic-deterministic boundary means that as models improve and are swapped in, the deterministic infrastructure downstream remains stable — the organisation benefits from better inference without inheriting the schema drift and silent correctness failures that come from conflating the two layers.
This compounding is the real return on investment in AI architecture. It is not visible in the first quarter, or the second. It becomes visible over years, as the gap between organisations that built deliberately and organisations that built frantically widens. The organisations in the first group have AI systems that genuinely know their businesses, that improve continuously from their own experience, and that can take on progressively more complex and consequential work as trust accumulates. The organisations in the second group have expensive, fragmented tool inventories that require constant maintenance, deliver inconsistent results, and generate the particular kind of failure — confidently wrong, invisibly so — that probabilistic systems force-fitted into deterministic roles are uniquely capable of producing.
Architecture is not glamorous. It does not make for impressive demonstrations. It is not the thing that gets discussed in conference keynotes or venture capital announcements. But it is the thing that determines, more than any other factor, whether the significant investments being made in AI right now will produce lasting value or join the long list of technology investments that promised transformation and delivered only complexity.
The organisations that will lead in the AI era are not those that moved fastest. They are those that thought most carefully — about foundations, about dependencies, about where probabilistic inference ends and deterministic execution must begin, about governance, and about the relationship between what they are building today and the capability they need to have in five years. That thinking starts with a framework. This one is a reasonable place to begin.
The Modern (AI) Construct framework referenced in this article is available as a slide deck and detailed technical guide. The framework is designed for use in structured conversations between business leaders and their IT and architecture teams about AI future-state design.