

Why most AI deployments are attempting to solve the wrong problems?
The technology is probabilistic. The business is not. Until leaders internalise this mismatch, the 95% failure rate is not a bug — it is a structural inevitability.

There is a question that almost never appears in AI strategy decks, vendor evaluations, or board presentations, and its absence explains more about the current state of enterprise AI failure than any other single factor: how much does the business outcome degrade if the AI’s output is 90% correct instead of 100%?
This is not a philosophical question. It is the most consequential design variable in any AI deployment. And in most organisations, nobody is asking it — because the AI conversation has been systematically framed around capability (”can the model do this?”) rather than reliability (”does the model do this identically every time?”). Capability is what sells. Reliability is what matters.
The distinction cuts to the core of what large language models are. LLMs are stochastic systems. They generate outputs drawn from a probability distribution. Given the same input twice, they may produce different outputs. The outputs are often excellent — coherent, contextually aware, analytically sophisticated. They are also, by mathematical construction, non-deterministic. And most business processes that touch money, compliance, safety, or customer commitments require outputs that are deterministic: the same input must produce the same output, every time, with no exceptions, no creative variation, and no confident fabrication.
This is not a temporary limitation waiting for the next model release to resolve. It is an architectural property of how these systems work. Treating it as a bug to be patched rather than a boundary to be respected is the root cause of most enterprise AI failures — and the data now confirms this at scale.
The Evidence Base
MIT’s 2025 NANDA study, based on 150 executive interviews and analysis of 300 public AI deployments, found that 95% of enterprise AI pilots delivered no measurable P&L impact. The headline has been widely cited. The explanation has been less widely absorbed. The failure is not model quality. It is flawed enterprise integration — generic tools that do not adapt to workflows, deployed into processes where their probabilistic nature is a liability rather than an asset.
The financial cost of that liability is now quantified. LLM hallucinations — outputs that are fluent, plausible, and wrong — cost businesses an estimated $67 billion in 2024. Not from dramatic, headline-generating failures, but from the quiet accumulation of wrong answers, degraded trust, and abandoned projects. In a 2024 survey, 47% of enterprise AI users admitted to making at least one major business decision based on hallucinated content. Nearly 40% of AI-powered customer service bots were pulled back or reworked due to hallucination-related errors.
These numbers describe an industry-wide category error: deploying a probabilistic technology into deterministic contexts and being surprised when the outputs are unreliable. The vendor ecosystem has no incentive to surface this distinction. Nobody fundraises on “works 92% of the time.” The marketing narrative is 12–18 months ahead of the engineering reality, and the gap is where the $67 billion went.
The Variance Tolerance Test
The corrective is a concept I call variance tolerance — a property of business processes, not of AI models. Every process in an organisation falls on a spectrum. At one end, variance-tolerant processes absorb imprecision without material damage: the output passes through human review, is advisory rather than executable, or operates in a domain where “good enough” is the performance standard. At the other end, variance-intolerant processes require exact, reproducible outputs where a wrong answer is not merely unhelpful but cascading — triggering financial loss, regulatory exposure, or physical harm.
The distinction is most vivid in manufacturing, where both types coexist within the same organisation. Consider a vertically integrated manufacturer controlling raw material sourcing through to after-sales service.
The variance-tolerant side of the house includes internal communications drafting, knowledge retrieval from maintenance manuals and SOPs, customer inquiry triage, competitive intelligence synthesis, training material generation, and meeting summarisation. These are real, valuable use cases. They are also the ones that populate every AI vendor demo, because they are the contexts where LLMs genuinely excel — and where imprecision is cheap.
The variance-intolerant side includes bill of materials validation, quality inspection pass/fail decisions, regulatory compliance filings, CNC program generation, lot traceability, MRP calculations, pricing and cost estimation, and safety-critical inspection records. In these processes, a hallucinated part number cascades through procurement, assembly, and compliance. A misclassified defect ships to a customer. An incorrect material cost flows into quotes, contracts, and margins. The cost of a wrong answer is not a bad email — it is a $200,000 tooling rework, a product recall, or a regulatory finding.
The pattern is consistent across industries. In financial services, drafting a research summary is variance-tolerant; generating a trade confirmation is not. In healthcare, synthesising clinical notes is variance-tolerant; calculating a drug dosage is not. In legal, summarising deposition transcripts is variance-tolerant; citing case law is not — as multiple lawyers discovered after submitting AI-generated briefs containing fabricated case citations and receiving judicial sanctions.
The variance tolerance test is Decision Gate #1 in any AI deployment: if the process is variance-intolerant, an LLM must not serve as the primary execution engine. It may serve as an input layer — translating unstructured human intent into a structured query — but the execution must remain deterministic.
The Compounding Problem
The risk becomes structurally dangerous when AI systems are chained into multi-step workflows — the “agentic AI” architecture that dominates current industry discourse. In these systems, each step’s output becomes the next step’s input. Errors do not add; they multiply. A material spec misidentified in step one generates a wrong bill of materials in step two, triggers an incorrect purchase order in step three, and produces a non-conforming part in step four. Each step looks locally plausible. The system-level failure is invisible until the defective product reaches the customer or the auditor.
This is not a theoretical concern. As one AI systems architect put it, agentic AI requires every step in the chain to be correct, predictable, and verifiable — and current LLMs cannot guarantee any of those three properties. The enterprises deploying autonomous multi-step AI workflows without deterministic validation checkpoints between steps are building systems that will fail in ways their ROI models never modelled.
Where the Real Value Is
The productive reframe is to stop asking “where can we use AI?” and start asking “where does our business have an information translation problem?”
Most organisations are sitting on two distinct information estates. The first is structured data — governed, queryable, sitting in ERPs, CRMs, financial systems, and databases. This data is already accessible to deterministic software. Classical analytics, business intelligence tools, and traditional machine learning serve it well. LLMs add little value here and introduce unacceptable risk.
The second estate is unstructured data — documents, emails, chat logs, spreadsheets, PDFs, slide decks, and the institutional knowledge locked in people’s heads. This data is scattered, duplicated, inconsistent, and largely inaccessible at scale. No prior technology solved this problem well. LLMs solve it genuinely well. The extraction, summarisation, classification, and translation of unstructured information into structured, queryable, actionable formats is the core value proposition of large language models in the enterprise.
The architecture that follows from this insight is not “LLM replaces the process” but “LLM sits at the boundary between unstructured and structured information, feeding deterministic systems that execute the business logic.” The LLM translates. Code validates. Humans approve. Systems of record execute.
This connects directly to the architectural argument in The Modern AI Construct — the five-layer framework (Systems of Record, Context Layer, Agents, Orchestration, Systems of Engagement) that places data quality and context architecture at the foundation. The variance boundary is the operating principle that determines how the Agent layer interacts with the layers below it. Agents interpret and translate. They do not execute. The execution remains in the deterministic substrate: the systems of record, the validated business rules, the governed data.
Organisations that collapse this boundary — that allow the Agent layer to write directly to systems of record without deterministic validation — are the ones populating the 95% failure statistic.
The Verification Tax Nobody Budgets
There is a practical corollary that most AI business cases ignore. Any LLM-generated output in a variance-intolerant process requires human verification. The time and cost of that verification must be modelled explicitly — and in many cases, it eliminates the productivity gain the LLM was meant to deliver.
Industry evidence confirms this. Companies deploy AI tools, get unreliable outputs, and must spend time verifying and correcting them. The time spent checking the LLM’s work frequently negates the time savings AI was supposed to deliver. This is a net-negative deployment: the organisation invested in the tool, trained people to use it, and emerged with the same or higher labour cost on the process.
The verification tax is not a reason to avoid AI. It is a reason to deploy AI in the right quadrant. In variance-tolerant processes, the verification overhead is light — a quick human scan of a drafted email or a summarised report. In variance-intolerant processes, the verification overhead is the process itself, at which point the LLM adds cost, not value.
The Smarter Architecture
The manufacturers and industrial conglomerates that are succeeding with AI have internalised this distinction. Mitsubishi Heavy Industries noted publicly that AI models trained on third-party data do not always produce reliable or replicable results — outcomes improve with proprietary data, but most companies do not have enough of it in clean, accessible form. Mitsubishi Electric developed what it calls physics-embedded AI: models grounded in physical laws and equations rather than statistical correlation, delivering reliable equipment degradation estimates even with limited training data.
The pattern is instructive. Use deterministic, physics-grounded, or rule-based models for variance-intolerant operations. Confine LLMs to the knowledge management and communication layer where variance is cheap. Do not ask a probabilistic system to do a deterministic system’s job.
This is the architectural insight that The Token Economy and The Ingenuity Ledger arrived at from different directions. The Token Economy demonstrated that the fully loaded cost of an AI agent, after accounting for infrastructure, guardrails, and error remediation, is roughly $82,000 against $135,000 for the human — a real but modest advantage that evaporates if the agent is deployed in the wrong context. The Ingenuity Ledger identified the institutional knowledge that disappears from the organisation when humans leave — knowledge that no current AI architecture captures automatically, and that lives in the Context Layer of the Modern AI Construct. You Are Not Behind on AI made the case that the prerequisite for any of this is operational self-knowledge — understanding what the business actually does before automating it.
The variance boundary completes the framework. It answers the question those articles left implicit: given the cost model, the knowledge architecture, and the operational self-knowledge, which specific processes should AI touch and how?
The Decision Framework
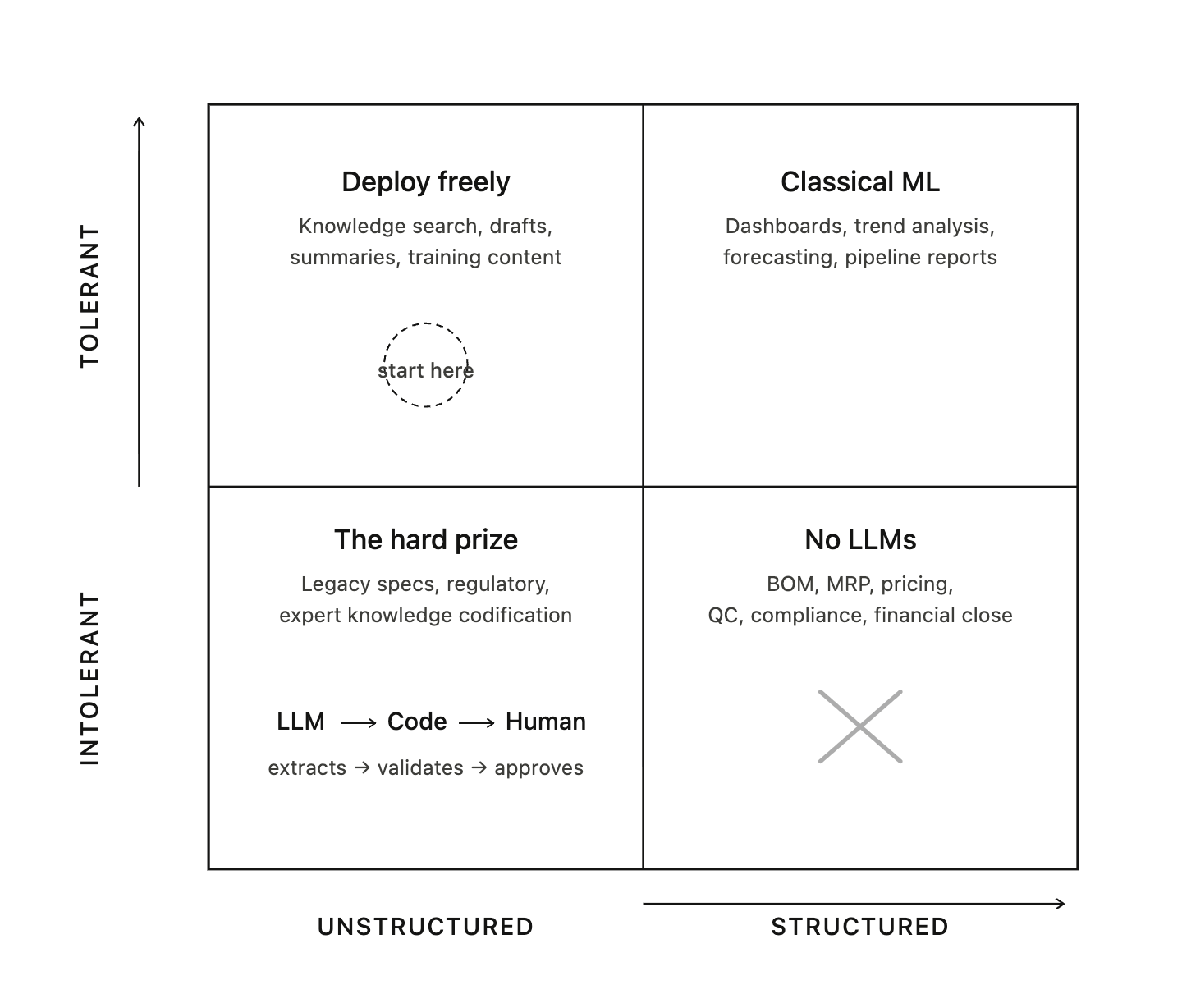
The answer is a four-quadrant model crossing variance tolerance with data type.
Quadrant 1 — Variance-Tolerant, Unstructured Data. The sweet spot. Deploy LLMs directly with light guardrails. Knowledge retrieval, communication drafting, document summarisation, competitive intelligence synthesis. Low risk, high visibility, fast ROI. Start here.
Quadrant 2 — Variance-Tolerant, Structured Data. Classical ML and BI territory. LLMs add value as natural language interfaces to dashboards and reports, but the underlying analytics should remain deterministic. Production trend analysis, sales pipeline reporting, workforce utilisation.
Quadrant 3 — Variance-Intolerant, Structured Data. No LLMs in the execution path. Use deterministic code, validated formulas, rule engines. LLMs may serve as a front-end translation layer — converting a natural language request into a structured system query — but the system executes the logic. BOM validation, MRP calculations, financial close, regulatory filings, quality pass/fail.
Quadrant 4 — Variance-Intolerant, Unstructured Data. The highest-value, highest-risk quadrant. Critical information locked in documents, drawings, tribal knowledge, and expert judgment, but errors carry severe consequences. The architecture: LLMs extract and structure the information, a deterministic validation layer verifies it, and a human approves before any downstream action. Extracting specifications from legacy engineering drawings, interpreting regulatory guidance, codifying expert knowledge into auditable rules.
The sequencing follows the quadrants. Phase 1 unlocks the unstructured data estate (Quadrant 1). Phase 2 accelerates communication workflows (still Quadrant 1, broader scope). Phase 3 bridges unstructured inputs to structured system actions (Quadrant 4, with validation architecture). Phase 4 enables decision support for strategic and operational judgments. Each phase builds the organisational capability — the data governance, the verification protocols, the human-in-the-loop discipline — that the next phase requires.
The Bottom Line
The 95% AI pilot failure rate, the $67 billion in hallucination losses, the 47% of executives making decisions on fabricated data — these are not failures of artificial intelligence. They are failures of deployment logic. They are the predictable consequence of applying a probabilistic technology to deterministic problems, without the architectural discipline to keep each in its proper domain.
The businesses that will extract genuine value from AI over the next five years are not the ones that deploy it most aggressively. They are the ones that understand its nature: a powerful, versatile, and fundamentally unreliable system for interpreting and translating unstructured information. Deploy it where variance is cheap. Keep it away from where variance is catastrophic. Build the deterministic validation layer before you build the agent. Build the Context Layer before you build the interface.
The variance boundary is not a limitation to be overcome. It is the design constraint that separates the 5% that succeed from the 95% that do not.
This is the fourth in a series on AI transformation economics. The first — The Token Economy — presents the fully loaded cost model for AI labour substitution. The second — The Ingenuity Ledger — identifies the blind spots in the replacement thesis. The third — You Are Not Behind on AI — makes the case for operational self-knowledge as the prerequisite. The architectural framework referenced throughout is detailed in The Modern AI Construct.